Google ha explicado a fondo cómo funciona una de sus mejores creaciones hasta la fecha.
Llegó en 2019, junto a los Google Pixel 4, y desde entonces se ha convertido en una pieza fundamental en el software de los dispositivos de la serie Pixel. La app de grabadora de voz parece una herramienta simple, pero Google ha hecho de ella toda una demostración de sus avances en los campos de la inteligencia artificial, machine learning y el reconocimiento de voz.
Recientemente, Google ha incluido en dicha app una opción que casi parece magia: permite detectar automáticamente si hay varios interlocutores en una conversación, y etiquetar las intervenciones de cada uno de ellos, para posteriormente asignar etiquetas en la transcripción de la grabación (dichas etiquetas pueden ser cambiadas por los nombres de los interlocutores más tarde por el propio usuario). Todo ello sucede en tiempo real y en el dispositivo, sin necesidad de conexión a Internet.
Aunque el funcionamiento parece simple, detrás de esta función se esconde una tecnología muy avanzada, que Google ha querido explicar con todo lujo de detalles.
La app de grabadora de los Google Pixel es una de las mejores herramientas creadas por Google hasta la fecha.
El procesador Tensor da vida a una de las mejores funciones de los Google Pixel
En la publicación de su blog centrado en avances relacionados con la inteligencia artificial, Google explica que buena parte del sistema de etiquetado de interlocutores actúa en el bloque de la CPU de Tensor, el procesador integrado en los dispositivos de la serie Google Pixel desde los Pixel 6. No obstante, en un futuro pretenden delegar algunas de las tareas en la Unidad de Procesamiento Tensorial (TPU) para reducir el consumo de energía.
El funcionamiento de esta función se basa en un sistema de diarización de interlocutores llamado «Turn-To-Diarize». Su cometido es el de crear modelos de machine learning optimizados, para conseguir segmentar según el interlocutor horas de grabaciones de audio en tiempo real, utilizando los recursos técnicos disponibles en los Google Pixel.
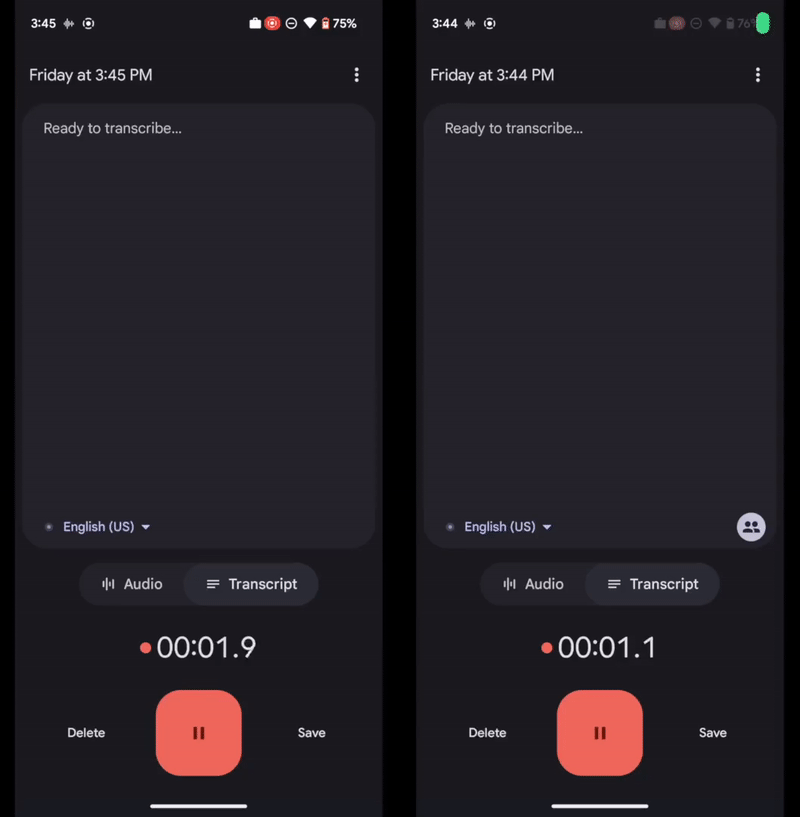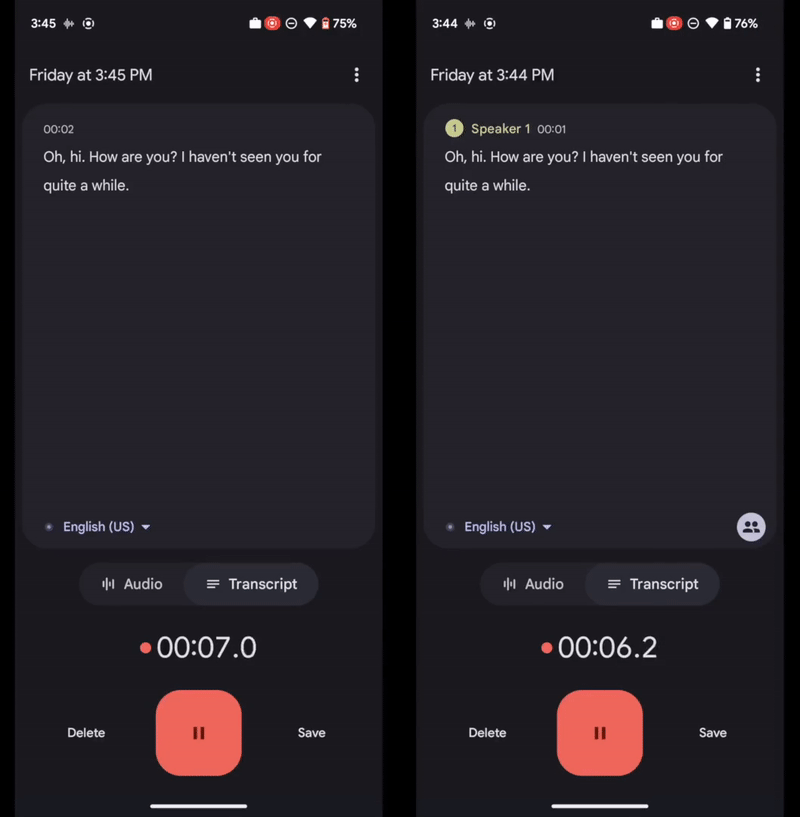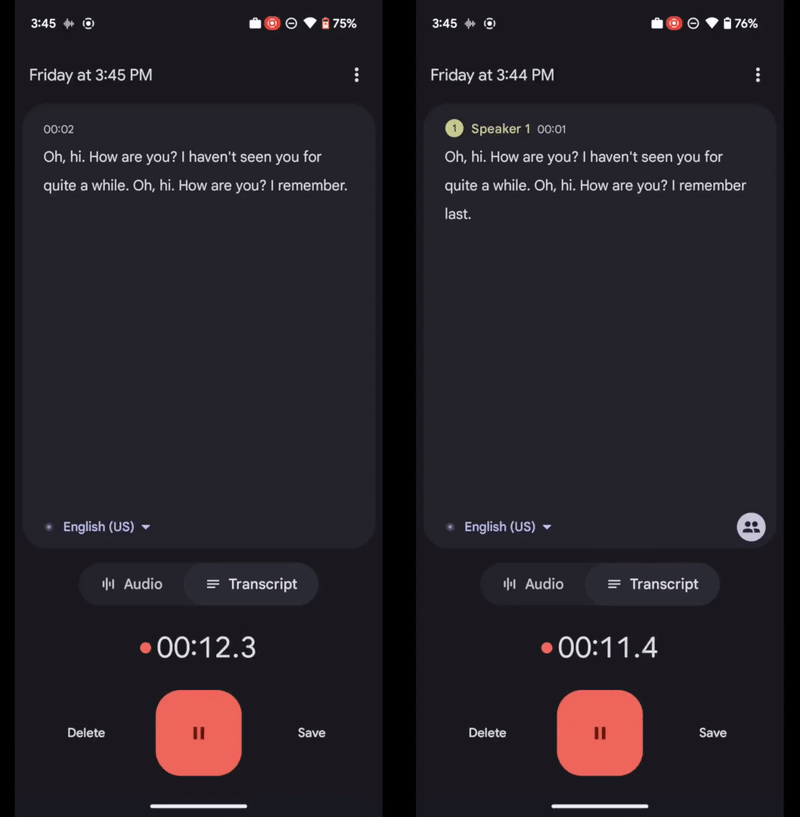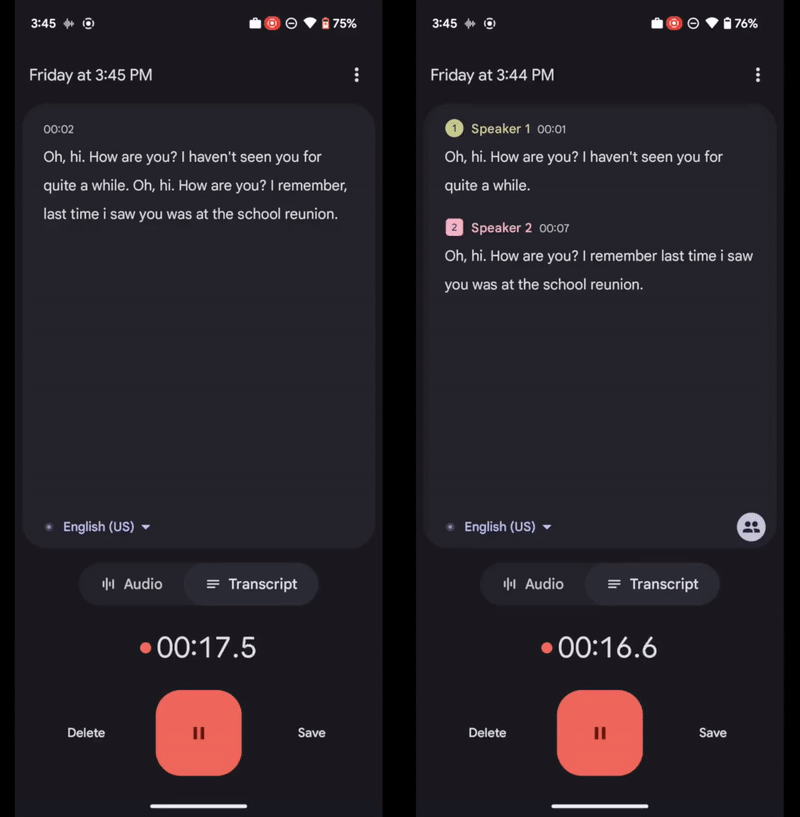
Google ha combinado varias técnicas diferentes para hacer funcionar con efectividad este sistema. Por un lado, es capaz de detectar cada vez que hay un cambio de interlocutor en la grabación a través de un modelo de codificación encargado de extraer las características de voz de cada persona.
Por otro lado, un algoritmo de agrupación es el encargado de asignar las etiquetas a cada una de las personas que participan en la grabación.
Una vez segmentada la grabación de audio en turnos de locutor homogéneos, utilizamos un modelo de codificador de locutor para extraer un vector de incrustación (es decir, un vector d) que represente las características vocales de cada turno de locutor.
Uno de los rasgos más llamativos de esta función es que aprende de sus errores con el paso del tiempo. Google explica que, conforme el modelo va analizando cada vez más audio, es capaz de asignar con mayor precisión las etiquetas, e incluso puede hacer correcciones en etiquetas asignadas previamente.
En nuestro sistema de diarización de locutores en tiempo real, a medida que el modelo consume más entrada de audio, acumula confianza en las etiquetas de los locutores predichas y, ocasionalmente, puede realizar correcciones en las etiquetas de los locutores predichas anteriormente con baja confianza. La aplicación Grabadora actualiza automáticamente las etiquetas de los hablantes en la pantalla durante la grabación para reflejar las predicciones más recientes y precisas.
Resulta bastante increíble que todo este proceso se pueda ejecutar en un smartphone sin necesidad de recurrir a ningún tipo de conexión con un servidor, y en tiempo real. Y, aunque a día de hoy la asignación de etiquetas automática solo está disponible en inglés, se espera que en un futuro la función incluya soporte para varios idiomas.
Ver Comentarios
Fuente info
Autor: Christian Collado
[su_divider]